




Often in life, there are these small time frames where you age by years mentally, and I recently went through such a phase again. I was on-road in the SF Bay Area. As we entered 2024 at Crunch, we had much more clarity and a lot of open-ended questions.
Founders struggling from the sidelines look very stupid. I've put myself in the imaginary shoes of some of these founders numerous times in the past and made baseless comments. Only those who have their hands dirty know what it truly means to build a company. And it's nowhere synonymous with being easy.
As I dive into my learnings below, respect is the first adjective on top of my mind. I've always respected entrepreneurs, but having been on this journey for a while, today's respect has reached previously unknown levels. Reading books like 'Hard Things About Hard Things' or 'What It Takes' or ‘Tape Sucks’ or 'The Mom Test' or 'Obviously Awesome' amongst others without being an entrepreneur is one thing. It takes a very different flavour if you've battled for a while and then re-read it. Try it sometimes if you're a struggling entrepreneur, and you'll thank me.
Evolution of our positioning
Before we go onto the US trip, below is a summary of the general evolution of my thought process. Previously, we had established that general business analytics made more sense for us. Also, smaller companies don't have a strong opinion, and they have a lot of low-hanging fruits in all directions to focus on data issues seriously enough for us to base our foundation on their needs. We also established in my previous post why looping in analysts as a user instead of sidelining them makes more sense. Naturally, as we spent time talking to more people, the message we picked for ourselves looked like this.
We were a happy bunch. It looked like we had worded things out well, and now the next area of focus was communicating how our proprietary library of functions made all the difference. If the world worked the way a founder wanted, everyone would be a billionaire. It dawned on us that people were still confused. What's wrong with positioning Crunch as an AI agent? A bunch of things, I learnt including:
A zillion AI agents exist in the world that have been under-delivered.
Everyone needed clarification about how our AI agents get the nuances of their system.
Agents typically always replace the level 1 folks, which meant we were walking into rooms where people would assume us to be a replacement to their analysts.
The repositioning
We hit the drawing board again very quickly. It was one question that made all the difference. I was in an intense pitch, and either I did a terrible job or the listener was distracted. However, towards the end of my 5 minutes of enthusiastically explaining came a question - How is this different from Chat GPT? This question changed everything. My first reaction was 'Are you kidding me?" but as founders, there is a phenomenal ease with which we take questions that surprise you. I realized that while we were making it easy for people to leverage LLMs, we were adding a lot of value under the hood, which was never communicated. We were overpacking stuff under one layer called an AI agent. So, we kept the product as it was and changed our messaging to what gets summarized in two sentences.
It will become a competitive disadvantage if you don't leverage LLMs a few months later. We help you prepare your data (through a semantic map) and provide a modular AI interface (our notebook) so that you can leverage any LLM's capability.
And this is what we say now to everyone we talk to. So, what's happening under the hood? The following:
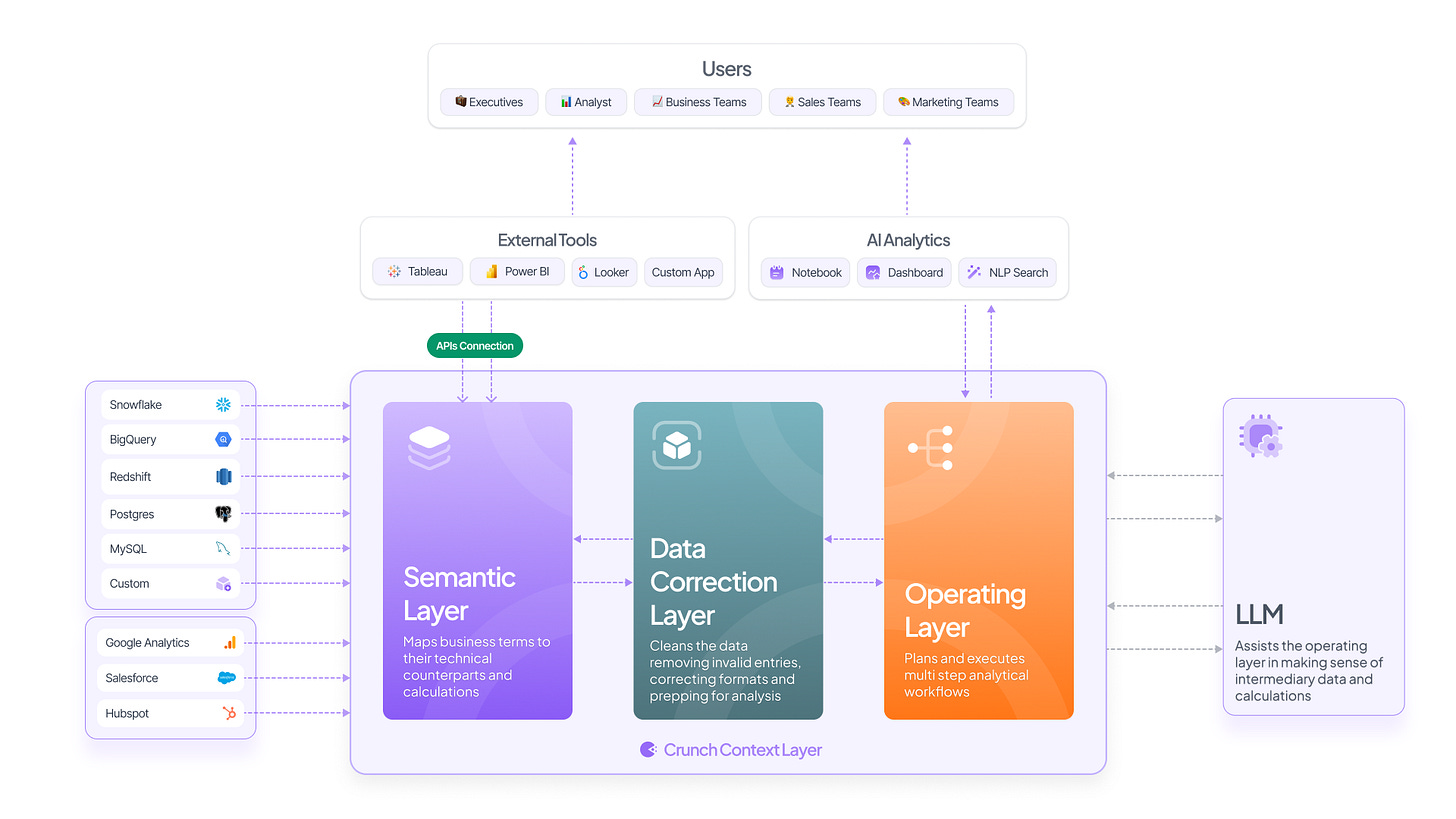
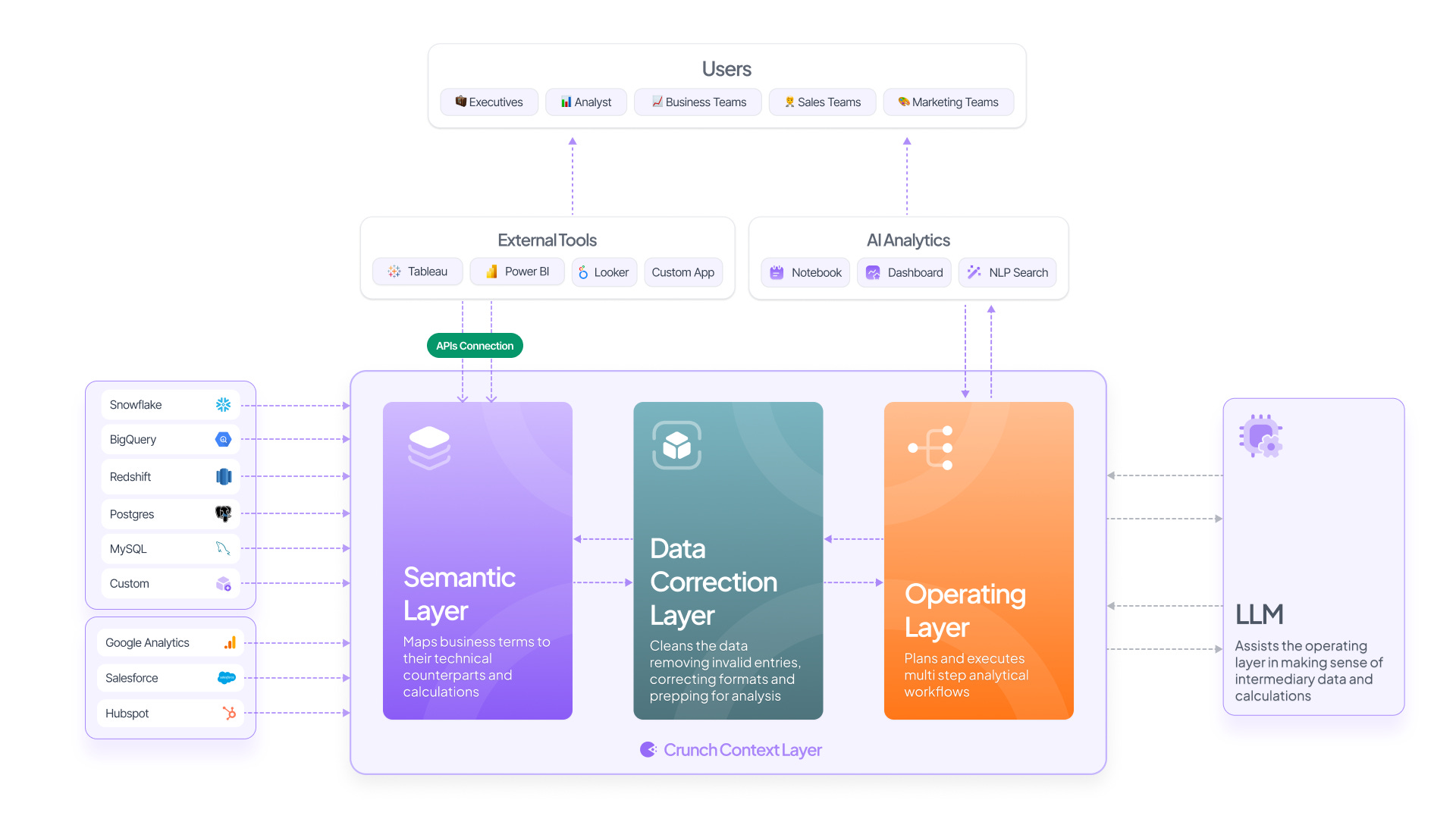
We map a semantic layer. This semantic layer has logic around what table will be queried for a business term, what operations will be performed between various data points across tables, and which filter will be applied for which persona. Every org has 1000s of tables in the backend, but the semantic maps become the true source of truth. This takes care of data reliability issues (no dashboard in the org on top of a semantic layer will likely have mismatch issues) and becomes an excellent table to feed into an LLM. The semantic layer on its own can work with any of the BI systems across the org.
On top comes the data correction layer. This is where our AI agent does most of the data wrangling. Analysts do three things broadly: First is the routine analysis of features, campaigns, products, etc. The second is an ad-hoc analysis where a senior stakeholder walks in with ad-hoc asks. The third is open-ended exploratory analysis and RCAs. No analyst likes to spend time preparing data, and all three of these scenarios take as much as 60-70% of the analyst's bandwidth. On top of the semantic map, the data correction layer becomes an analyst's trustworthy, reliable assistant.
The last layer is the operation layer. Using the library of functions, the operation layer is where our agents, which can be purpose-built for specific tasks (such as forecasting or churn prediction), come in. This layer sequentially goes through a causation workflow, surfaces the queries it is writing, and leaves the analyst in control. This can be used directly by the data team or can be customized for stakeholders to interact with directly. When a data team interacts with it, the interface remains notebook-heavy, but it becomes NLP-based when a non-technical stakeholder interacts.
US customer discovery sprint
We planned a discovery sprint over 13 days. This was intense and involved a total of 64 meetings with about 50 in-person meetings, 5.5K USD of expense in all throughout the sprint (all inclusive) and a total of 852 miles or 1372 km in commute leaving the flights out. Most meetings were pre-planned with chosen stakeholders. Below, I’m highlighting some significant learnings. Most of these points have contributed to our plan of action going ahead.
Verticalization is critical for us. Without a specialized approach, there is a general lack of trust and rightfully so. Not focusing on an industry/set of tools makes us look like another average player. Also, from the analyst's PoV, terminologies make a lot of difference. For example, the 'load factor' in the case of a cargo company might be very different from the 'load factor' in the case of an airline company. The load factor in cargo can be fractional as a number, but in the case of passengers, it will always be a whole number, and a 90% load factor will mean different things and have different impacts on the calculation of price. To get to verticalization, we will follow a service agency route as a transient route. More on this below.
Those who understand what we do genuinely will likely perceive us as a replacement for ThoughtSpot, Data Iku or Alteryx. The kind of customers that need something like ours the most are non-digitally native. After the first ten paid customers, Crunch will bring on board some advisors with experience in selling at these three companies or with deep connections in our target market to scale this up.
Ultimately, the goal should be to get the head of data or whoever our PoC is promoted. When I ask data leaders which tool has helped them get promoted, no tool comes to their mind. Most folks out there opt for the safe route. For example, if they use Big Query, Databricks and Snowflake, they don't need much enhancement in the tool stack. Promotion happens when RoI is impacted. However, mapping RoI to what we're serving through the tool is very, very tough unless you've worked in a very custom manner with each customer. Even the head of analytics needs to learn how to go about it, but in their words, saving time is an okay value add, saving operational cost is a better value add and increasing RoI is what we should strive for.
From the lens of product marketing, a query-free world might be a better word to use than an analyst-free world. It gels well with people. Similarly, aiding analysts or man-in-the-loop builds confidence over the narrative of 'replacing an analyst'.
The semantic layer is a massive value-add when you position it as a single source of truth for all your data. Companies like Intuit value this as a 6-7 digit (in terms of USD) level of problem. On the other hand, AI agents have fatigue associated with it. The bottlenecks are the time to deployment and what the semantic layer looks like. We're working hard to figure out how to get customers to have a shorter time to value and better clarity on what the abstract semantic layer under the hood does. We will need a lot of libraries of use cases and examples for people to see the value and the impact of something that stays under the hood and is virtual in many ways.
Brands that are non-digitally native and likely to grow into massive logos have numerous tangential problems that make entry a bit slow. For example, a car manufacturer going against Tesla wants our solution, but the first step in helping them is handling their data collection. This distracts us, but we could co-sell a product if we identify the right partners to collect data. We're thinking about this at the back of our heads.
Got some excellent exposure to the pitfalls of deal flow and budget owners. The founders I spoke to saw their deals post a paid pilot get ruined because of budget owners and shared functions. For us, having a clear-cut budget owner defined from day one will be very critical, given the nature of the product. As such, pilot templates are very critical. Mature organizations navigate pilots best through pre-agreed documents, laying step by step what the milestones are, how they are going to be evaluated, and when a pilot becomes an ARR conversation. We may have seen slow responses because of a lack of this workflow and mostly because we never needed one until this point in time. We're working on it now.
Our product resonates better with rev-ops or success-ops folks than with CRO or Head of Customer Success because of the myriad of other important things on the plate of CRO and Head of Customer Success. This means the best person to make a champion is the ops head of the function or, else, a VP who might be one or two ranks below the corresponding CXO. As we focus on CTO and CIOs, dev ops might be the right person to speak to as well. A simple use case such as we help you save your AWS cost by 100K USD per month because of query time and data structure optimizations might become highly relevant.
Sports Clubs also came across as very interesting verticals. These clubs spend millions based on insights that are derived through old-school tools like Excel. We've initiated conversations with some of the clubs. We will see how this goes. This is not a vertical you can flirt with, so unless we’re determined to niche down on them, we will likely steer clear of them.
One another relevant insight was that someone like a semiconductor provider has 100s of billions at stake with every incorrect insight. For example, if Apple stops taking chips from a provider, the provider is doomed. So these people have very old-school methods, and they will likely never adopt an unfinished or, for that matter, even a finished tool.
Healthcare as an industry is left on the fence for now. Given the regulations around PII, there are requirements such as anonymizations, redactions, etc, which would be a distraction for us.
Spoke to a few Insure-tech PoCs. At the surface level, it looks like insurance companies have a lot of data, and they are terrible at targeting. However, the use case that's genuinely of significance to insurance providers is claims evaluation. The criteria for claims differ largely from one insurance type to another, leaving a lot of ground for errors from an AI-powered company. We will, for now, leave this industry to the side.
I dived a little deeper into how CFO offices evaluate the solution as well. Most of the CFO office folks face issues with reconciliation. Most of the CFO office folks know where the number will lie. They don't need an analytics person to figure out what that number needs to be, so the use cases are more granular, for example, how many users did X, what is the total value collected last month, etc., because these things already have an idea about. So, for the CFO office, forecasting AI agents becomes supercritical. The angle of what is influencing my sales, what is influencing my cash outflow, what I should do right now to improve my metrics for the future, what I should do to have a shorter billing cycle, and all kinds of what-if scenarios matter a lot. Collections and Account Receivable software is what people mostly buy in the CFO office first. The next step is operation optimization once this is bought, which is the case with every Series B company. Being on the Gartner Leader Quadrant and Forrester quadrants helps you get in when selling to the CFO office. Also, things like how the office ranks against the counterpart CFO offices in other countries also matter a lot for the CFO office. Because of all these granularities, we're parking this vertical on the side as well.
The unrecognizable product category is a challenging sale in this market. Using the world semantic map or AI agents makes things easy, though the discussion then centres around replacement. As highlighted above, positioning change has swayed a few things in our favour. We will see how this all evolves. Also, in the non-tech category, we learned something interesting. In this market, it's best to avoid use cases such as drive upsells. Use cases like these have become rare off-late. The use cases that help people sell the core product are what matters. The whole industry (more so non-tech players) wants to just double down on what's working.
While thinking about industries, the qualification criteria shift massively. Someone with a 100-million-dollar revenue in energy might still be a small player. Similarly, energy companies that have crossed Series C funding might still be early in their journey. Also, quite a few meetings were focused on understanding the nature of the beast (enterprise). As companies become bigger and older, they become territorial. This means that someone like Albertsons or Macy's will always prefer reliability, and for them, reliability is much more valuable than efficiency optimization. This means that the Semantic layer as an offering is super valuable for Macy's.
While analysts do either RCAs, Ad-hoc analysis or regular queries, true Ad-hoc happens only within very large organizations. For some organizations, things like ad-hoc analysis will likely make us look like an irrelevant value add.
Most non-tech companies will likely prefer embedding support. This is based on feedback from someone who has worked with these non-tech companies. Embedding because they have their own in-house tools, and they would want us to support widgets in their tools as opposed to a full-fledged cloud-based UI of its own.
The names people often confuse or compare us with are Hex, Treasure Data, Atlan, Hevo Data and sometimes even Databricks. It's funny how everyone knows about Alteryx and Thoughtspot, but no one brings up their name unless we do. Understanding how we fit into the puzzle if someone is using any of these companies is very important. We've done and will keep on doing an elaborate exercise around that.
0-1 business expert AI agents are also very interesting because people are generally bad at this, and the impact is very direct. Also, from what we know so far, the majority of the analysis can be automated, if not entirely. What does that mean? Everyone is good at doing their current business, and they know they need to do some new things. Big companies, specifically the non-digital native ones, have a lot of pressure on this front. Based on a cohort of users and conversations in places like community and customer support, there can be patterns that can be identified. For example, what are people mostly searching for? What are the first five actions people take when they come on board? This company I met helps set up an event website (such as a wedding website) for people, so the analysis was mostly done on steps taken by people after they get started and land. Looking at data and highlighting patterns could actually also help the data science team figure out new business expansion, and this actually even gets them promoted.
A ruthless focus on big logos is very important. We chose the service route in the beginning for a reason. We're in a crowded market, and we're nowhere close to having the kind of connections, the kind of runway, and the kind of tech and marketing talent that some of the data domain incumbents have. Going the service route is necessary not only to get some form of PMF but also to help you get some big logos that help with the absence of all the pointers I wrote above. So, if we're going the service route, it's very important to focus on big logos as opposed to smaller ones.
Use-case-based marketing is what we will be focussing on going ahead. As a small-scale company, we need to have an opinion. More so because we're not present in the valley and because incumbents will also try to do what we're doing.
There are equally smart, if not more, kinds of people sitting in the Bay Area doing what we're doing that too over Facetime. That puts us at a massive disadvantage. When you meet someone in person, they remember you. People have gotten back to me on their own on a phone call. Some more active on-ground presence in the US is being worked upon.
The maths with a B2B2B kind of offering just doesn't work out. A company we spoke to is spending a total of 700K in the next six months building their semantic layer and an AI-powered interface. And then maybe 150K or so of maintenance costs per year follow. They want to charge about 500 of their retail customers, not more than something like 2000$ per year, because these customers already have 10K USD or so ACV for the company we spoke to. The unit economics work against us, so we will likely stay away from B2B2B deals.
India is transactional, where the US is relational, and the US is transactional, where India is relational. In the US, people care about whether you remember their daughter's name (Relational), whether you talk about the Superbowl or whether you connect about rock climbing before you get into a pitch. In fact, I connected with people on lactose intolerance funnily. In India, you can get into a pitch in the first minute itself (transactional). In the US, it's okay to always have a paid pilot (transactional), whereas in India, we go and offer discounts because of personal relations (relational). This mindset harms us. When we speak to someone from the US, they will remember us less if we're too transactional, whereas they are relational. Cultural nuances have never felt this important.
Phone calls as a channel have worked wonderfully for a few other founders targeting similar kinds of companies. The iMessage over email culture is real. This is a channel we will have to eventually do something about because, for us, what has worked the best so far is Linkedin.
Thoughts on the semantic layer
We believe that Semantic Layers will pick up. Broadly put, a semantic layer makes the answer deterministic vs probabilistic. When AI finds its actual adoption in Data Science, data reliability can only be achieved through a semantic layer. So far, many have managed to work without a semantic layer by
Ignoring the problem (this is surprisingly high and the primary reason why most companies have data reliability issues) or;
Deploying extra workforce (which as a solution fails). Regardless of whether an organization has an intentional semantic layer strategy, one (or multiple) will form naturally any time humans interact with data. Humans become the semantic layer. This doesn't scale well and will not age well, either.
Developing an in-house system (which may or may not be enough for the AI, depending on how robust the system is). Organizations that build it in-house usually create business-ready views via Data Marts. This is mostly because Data warehouses, designed for architectural integrity, present difficulties for direct business user analysis due to their normalized structures. However, this always leads to static and inflexible definitions. This inflexibility, coupled with performance issues for user queries on large tables, often drives users to extract data into analytics platforms, further contributing to semantic sprawl.
Rely on tools that allow semantic definition at the data pipeline level. Without a formal strategy or governance, data engineers might embed semantic meanings into their pipelines to meet analytics needs, leading to inefficiency and semantic sprawl as they repeatedly encode common business concepts across different pipelines.
Rely on tools that have a semantic layer as a layer before dashboards, reports and spreadsheets. Since there are multiple analytics tools in any organization, it inevitably leads to the isolation of definitions, known as semantic sprawl, which occurs because modern organizations typically use numerous analytics tools for different purposes, leading to inconsistencies in key data concept interpretations.
We're getting further clarity on why people have ignored the problem. From what we know so far, it looks like semantic layer setup is something most organizations dread. Initially, there is no need to have a semantic layer, and when the growth stage finally comes, the setup, which may take months, takes a backseat, and that makes the whole problem worse. Orgs have postponed it, which was okay until now as there was no massive business disadvantage (business still survived). However, in the age of AI, being unable to work with LLMs may be an enormous competitive disadvantage. Specifically given how pressed everyone is going to be to optimize for RoI. However, we're still evaluating other intricate reasons that may have caused companies offering semantic layers (such as DBT Labs, At Scale and Cube) to grow at the pace they have grown. The pace is good and picking up (which is always a good sign), but there must be other reasons why not every org in the world uses these existing players already. If it's just a market penetration or presence or targeting issue, we have an in, and that's brilliant. One thing to also note is that the existing semantic offerings usually pair it with other offerings. At the very least, the use case is not just a single source of truth but time saved in running queries because of the semantic layer.
How to look at the Semantic Layer as a Market?
I want to establish that semantic layer companies don't necessarily call themselves semantic layer providers. The market is very well established if you think of it this way, and many, many, many companies still need a semantic layer, leaving opportunities for everyone to expand into. Some organizations call semantic layer as a metric layer. Thoughtspot also does a semantic layer and has its own terminologies. Then, consider Treasure Data, for example. They are a CDP, and all CDPs are essentially semantic layers for customer datasets. CDPs are an excellent fit for the CMO's office. Similarly, companies that offer services to a CFO's office, such as DriveTrain and Anaplan, have elements of the semantic layer for their respective verticals built in.
Semantic layers have been an essential part of the modern data stack ever since its evolution. They are often found within another technology of the stack — localized either within a BI tool or within a database–or through implementing semantic logic in data transformations in the ETL/ELT process (examples were cited in just the previous paragraph). Decades after its original development, the semantic layer is rising to prominence again, in large part as a response to the shortcomings of self-service BI. Semantic layers are evolving as a stand-alone entity. All the semantic layer providers (DBT, At Scale, Cube, etc.) picking up in the market today provide a layer decoupled from data sources and from BI and analytics tools and situated between the two. This trend will likely continue. Semantic layers consolidate the view of the organization’s data and capture business entities and analysis terms. Thus, the designated audience of the semantic layer isn’t limited to a specific subset of personnel with certain skill sets; it’s actually the entire organization, regardless of individuals’ technical ability.
Thoughts on data space
A lot of folks came to us with objections that are justified. Data is a tough space to crack. While those objections are all valid, it takes someone delusional to believe in a shift and make that shift happen. Secondly, markets shift every few decades. Data as a market will always be competitive, but the players that genuinely matter a few years down the line might be very different, and whether we can see who they will be is something that likely none of us can claim to be an expert in. So, naturally, I've been thinking deeply about the space itself.
Analytics engineering is going to change massively. Companies are looking beyond the age of collaboration to being an end-to-end platform. To a large extent, AI is the reason behind all this. Let's dive into the details below.
The Snowflake IPO tipped the market in favour of everyone building in data. Suddenly, everyone wanted to build and invest in data offerings. Too many companies have come up too quickly. This has resulted mainly in fatigue around being a modern data stack offering. Some products will likely become less relevant but will never die (concept of halflife). In the data world, there is a commonly used phrase, Modern Data Stack. Companies like FiveTran were built around that. A while back, it was okay for someone who was an ETL pipeline tool to go on and partner with someone who was a Warehouse and collectively, they both grew. The advancements in AI and the competition, thanks to tons of money in space, have forced everyone to attempt to deliver end-to-end offerings. The age of collaboration is falling behind. This is reflected in how tools like Databricks are growing (they will likely cross Snowflake in a couple of months in terms of ARR).
Why? Because of AI, many of these new-age tools can achieve what would previously take decades of coding. This means a few bigger players can make some acquisitions and serve everything covered under Modern Data Stack. This also means anyone building for Data is up against the best of the players. Essentially, building something that will blow up the internet has become exponentially more challenging and will likely become rarer.
On the point of acquisitions, history has shown acquisitions are a headache. What we see as a product merger is just the tip of the iceberg, and 90% of the mess of merging two technologies is invisible to human eyes unless you're the engineer tasked with it. You can build something from scratch faster using AI. The question is, when will the revenue from these smaller players popping up become relevant for a giant like FiveTran to notice and make efforts (whether that is to acquire or build on its own)?
Thoughts on AI being a commodity in future
Given how many startups are popping up in data space and given how AI is no longer exciting for people because they have seen bad results through AI or they understand that most of what someone is offering as a tech layer might gradually become the norm and not that big of a deal. It looks like the AI layer is getting commoditized. IT would be stupid not to plan for a future where even the semantic layer might get commoditized.
Now, what's a commodity? Think of coffee. Everyone needs coffee, but it doesn't really matter where coffee comes from. Commoditized stuff is no longer a big deal. This means you will have to be creative in selling a commodity because if it's too easy to develop, say, the commodity, all traditional data players will likely have that in-built very, very soon, including folks like Databricks. Signals of this being a commodity is apparent because ‘Text to SQL’ is now everywhere.
And how can you be creative in selling a commodity? Have use cases such as ‘we help you find the next best step based on a connection with your CRM’ as opposed to being just a semantic layer. Or ‘based on your data, here are the new market expansion opportunities’ (this is a use-case we’re planning on piloting with someone on already). This needs an industry niche, and one might have to get deep into workflows. On the coffee example, people came with coffee on the go through a coffee blender, straw coffee, cold brew, etc.
Why am I thinking about the future while picking a niche? Picking a niche needs three things.
What can we sell to / distribute efficiently?
What can we be good at or have an unparalleled technical advantage?
Where do we have a long-run survival strategy?
Looking forward as we walk might help with avoiding surprises. Call it an attempt at developing an adversarial thinking. Understanding and preemptively addressing the challenges posed by competitors and the market will significantly impact how quickly you find success.
What have we learnt from customer responses so far?
Our target market is non-digitally native businesses needing a semantic layer and 50 Mi+ in revenue. The functional roles we're approaching in these businesses are the CTO / CIO and COO functions. We're speaking to companies who see issues with their data reliability and lack a single source of truth as far as their data goes.
Our ACV would be 25K USD per year at the least, and the average ACV should be 50K USD or more per year with very high upper limits.
How is our semantic layer different?
We have a low-code deployment, and we support the creation of semantic layers using languages like SQL and Python, which means you don't have to learn scripts native to other semantic layer providers.
On top of that, we provide an AI agent. However, the core qualification criterion is that the company needs a single source of truth. Companies that have set up ETL pipelines or have just started setting up warehouses or have matured enough to need a data catalogue are great for us to speak to. We may see some collaboration with these companies, too.
Lastly, we do On-Prem deployments. We learned from our conversations that many folks don't have these offerings because no one chose on-prem deployment. While On-prem has its challenges, it's not something we're necessarily opposed to in any way.
What industries are we targeting?
This is still primarily based on what we know so far. However, these are the companies we're targeting. We want to get more vertical, and how we plan on doing that is explained below. But the industries in our target are:
Retail Players with 500+ employees and 50Mi+ ARR
Logistic Players with 500+ employees and 50Mi+ ARR
Airlines with $1Bi+ in Revenue
Energy companies with $100Mi+ plus in ARR
Real Estate Companies with 500+ employees and 50Mi+ ARR
Education Institutes with $25Mi plus ARR
Why chose the office of CTO/CIO and COO?
We can technically sell to all the following offices, including the office of CRO, Office of CFO, Office of CMO and Office of CPO. However, for the CPO and CMO offices, decently established reporting capabilities are available through self-serve tools, which have established themselves as incumbents for those functions.
The CRO office has a ton of small players and also Salesforce Einstein. While it's different from what we're trying to do, this is not a battle we have a solid reason to pursue yet. The Office of CFO has used cases we're yet to become familiar with, and some players like Anaplan, Hightouch, DriveTrain and Cube Software (this is different from Cube and is a semantic layer for the office of CFO) have decent coverage in the market. These are both functions we can pursue later on.
A horizontal use case that we're curious about
The office of the CEO has a horizontal, industry-agnostic use case. And this we're pursuing. First, we don't know of a tool that does this, and second, because it's very well defined as a problem statement. The use case is to help the Chief of Staff prepare WBR, MBR and QBR reports without leaning on teams that spend weeks on QBRs, and it's recurring in nature. There may be more integrations needed if we decide to pursue this route more in-depth.
Can we deploy the semantic layer powered by others?
This is an open thread for now. As we're speaking to customers, if they prefer to deploy a semantic layer powered by an established player, we take that as a professional service task as well. However, this is just a transient stage. As we get clarity, we would either like to 100% build our own semantic layer or become the go-to partner for semantic layer deployment for companies like DBT, AtScale and Cube. We're more inclined towards competing because we believe our semantic layer is easier to set up, and there are open-source versions that can help us fast-track our development, which can then be repackaged as Crunch for customers. As a student of business, one thing I've learned is never to set anything in stone. We will see how this evolves
The current stage of deployments
Personal connects have been super effective for the time being. We have 13 ongoing conversations with decently well-known brands, and barring a couple of introductions, most of these conversations are with folks who came in directly due to a personal favour being asked of a friend.

If we map all these folks we're talking to into a grid of industry verticals vs the function they own within these organs and spread it on a grid, it's very spread out. This is very well understood and not ideal. But it’s the only way for us to get to the ideal stage of the right vertical, the right function and the right messaging.
We have a crucial task with these folks who signed an NDA. While we're confident that we can deliver a system that will impress them, the next step would be to sit with them and identify measurable outcomes and use cases for which the system can be tweaked. Our current pilots will demonstrate how our system behaves like analysts and can be used to assist them. However, efficiency alone is not enough to win deals. The product must evolve into use cases where we can publish case studies reflecting measurable outcomes.
How are we narrowing it all down?
We listed a bunch of pilots. Using these pilots, I also seek to achieve clarity on two fronts.
Taper deployments for industries that are not working well — ideally, one persona, one industry vertical, and a couple of use cases are what we want to get to. Our approach until that point in time will be to position ourselves as a professional service offering where, like water, we take the shape that needs to be taken and cater to various use cases. It's imperative that we pick our customer logos very carefully.
There is another outcome that we seek from these early pilots. These pilots will tell us where we have the most technological advantage. The choice of the vertical also largely depends on how confident we feel tech-wise and stuff such as what stacks we work best with and where our models are most reliable. This needs a careful evaluation of how the other data players have evolved, the metrics they base their success on, the kind of customers they target, and the part of data play they operate in. Theoretically, whatever has to be researched is primarily done. With the implementation of our product, more clarity will surface as we get our hands dirty with real-world use cases.
So what does the two-member GTM team do meanwhile? We test two things.
#1 Agency Pitch
The first is nailing down our agency pitch. We have picked big logos across the chosen industry verticals for the outbound motion related to our positioning as a service agency.
We have identified pawns in these companies, who will be our first point of contact. Pawns are senior leads and managers with visibility into the company strategy and granular visibility into how the teams operate. Pawns tell us about the high-level problems,
Our champion will be someone we can get promoted. This is usually one or two levels below the budget owner. We prepare a custom service deck and send these champions a hyper-personalized outbound message. We work with them to validate our assumptions, define better use cases, how to measure success and failure, do time and cost analysis, and get buy-in for the budget. We become butlers.
Next, with a proper time cost analysis and ideas around what a working PoC would look like, we go to the budget owner. The champion takes the credit. We sign off a paid pilot and get into implementation.
Pilots will have clear-cut deliverables and time-bound phases. Once the pilot is over, we move into an ARR contract.
#2 Partnerships and Marketplaces
The second motion is partnerships and marketplaces. We're on the lookout for companies who we can piggyback on. These partners can be data players with complementary offerings such as Atlan. These partners could also be consulting companies such as Accenture. For the complementary offering, we're already mapping out our competitors. As we get a few case studies, getting listed on marketplaces and figuring out our commission models that ensure we get floated around as a preferred partner would be very important. For the other half, companies like Accenture have a distribution network, and they keep looking out for offerings like ours, which helps them position their services under the AI transformation bucket. With the Accenture route, we become the backend and lose direct interface with the customer, but in the early stage, it might still be worth it.
#3 Open-Sourcing a part of our project
Since we're up against established names, the best way to build trust in dev teams is to open-source a part of the project. Devs duplicate Git Hub repos, and this is something that's pretty much a habit for them. People like to try new things, and open source builds trust and has a high intent. If the developer likes it, there is word of mouth, and other developers try the product out in a team.
However, companies don't duplicate repositories. They like to purchase the tool so that all the headache around maintenance, support and innovation is on the vendor. This has played out well for other semantic layer providers and could play out well for us. Rest assured that technically difficult things, such as what our AI agent does, will never be pushed to duplicate.
Questions top of our mind
Who in our network can open doors to the right kind of customers? We need paid pilots, and we need these pilots to happen with bigger logos. No meeting we're going into is resulting in disappointment, so if you make an introduction, chances are the other side will be happy to chat :)
How do you crack a complementary partnership? If someone who has deployed Atlan or Bigquery is going to use us, can we help them, and they can help us? This needs us to pick an upcoming company that is hungry to grow. If you think you can help us on this front, hit reply, and I'll share details.
A big question to still evaluate is building our own semantic layer as opposed to being a preferred deployment partner for someone like DBT. We have opinions here, but this will need more evaluation.
On-ground strategy in the US. We might make some temporary moves to drive this motion forward. Non-digitally native companies are not just mostly on the East Coast, but they also operate in different ways. We have quite a lot of work to do here.
Lastly, we may try some traditional conferences like AWS, GCP, Databricks, and Microsoft Azure as an attendee and not as a sponsor. These conferences are brilliant spitting grounds for the right champion in our target customer base. For example, if Ryan from McD is doing a case study on how AWS helped McD save millions of dollars, Ryan is a great person to chat with. Figuring this out directly takes a lot of time, given our focus on non-digitally native folks. However, conferences are also a big waste of time if we're not careful about them. We're moving slowly on this front.
Cracking a professional service model. Eventually, we know the pitfalls of being a service company. This is new for us, and we have our eyes on the best of the folks who have done it in the past. A good part of our energy will go into cracking this.
That's all for now. This was a lot to digest, but if you read it all this way, I would like to speak to you. Believe me, it will help.
Until next time!